
NVIDIA 最近发布了 cuEmbed,这是一个高性能、仅使用标头的 CUDA 库,可加速 NVIDIA GPU 上的嵌入查找。如果您要构建推荐系统,嵌入操作可能会消耗大量计算资源。
嵌入查找是一项独特的优化挑战。它们是内存密集型操作,具有不规则的访问模式。cuEmbed 专为应对这些挑战而设计,其吞吐量是 power-law 分布式输入索引的 HBM 内存带宽峰值的两倍以上。
在本文中,我将解释嵌入查找是什么,它们为什么对推荐系统至关重要,以及 cuEmbed 优化技术如何提供卓越性能。无论您是直接使用 C++ 还是使用 PyTorch,我都会提供将 cuEmbed 集成到项目中的实践指导。
NVIDIA 认识到嵌入用例因应用而异,因此将 cuEmbed 完全开源。这使您能够自定义和扩展核心性能内核。
什么是嵌入查找?
某些输入自然会使用神经网络进行处理,例如浮点数向量或像素值,这些输入可以直接传递给卷积层或全连接层。
但是,大多数数据都是非数值数据,这意味着它表示为一系列类别中的一个选项。例如,考虑推荐的产品 (例如特定电影) ,以及类型或创作年份。
嵌入是一种将非数值特征转换为用于预测的浮点数向量的方法。 嵌入表 是一组与非数值特征对应的所有已学习向量。cuEmbed 中正在优化的核心运算是 嵌入查找 运算 (Figure 1) 。此操作具有以下特征:
- 获取一个或多个查找索引,这些索引表示作为输入引用的一个或多个类别。
- 从嵌入表检索相应行。
- (可选) 通过求和、均值或 concatenation 等方式组合这些向量。
- 为下游神经网络处理生成密集输出向量。
在 PyTorch 中,可以使用 nn.Embedding 进行单索引查找,使用 nn.EmbeddingBag 进行多索引查找。
生产系统中的嵌入操作规模巨大。典型的嵌入操作可能涉及从 O(1) 查找到 O(100) 索引,因此处理完整的批量可能涉及加载数万甚至数百万个嵌入行。有关更多信息,请参阅 来自 Ele.me 的推荐数据 和 来自 Alibaba 的用户行为数据集 。

学习嵌入向量需要向后传递,即从下游神经网络到达的梯度会传播回嵌入表。这在计算上类似于正向传递。在前向传递中,您可以收集并有选���地累积单个批量样本中索引引用的所有行。但是,在向后传递中,您可以从前向查找中包含该行索引的所有批量样本中收集并累积指定为单个嵌入行的梯度。
优化推荐嵌入和 cuEmbed
嵌入查找操作占用大量内存,在浮点运算中相对较少。它们非常适合 GPU,因为 GPU 的可用显存带宽为 TB/s(每秒数万亿字节)。
众所周知,要在 GPU 上实现高显存带宽,应跨线程合并访问。然而,图 2 显示,即使是相对较窄的访问,例如在嵌入表中均匀分布的浮点格式嵌入宽度 32 (每行 128 字节) ,也可以达到接近峰值的 HBM 吞吐量。如果在线程束中对齐和合并访问,则不同的线程束可以访问不相交的内存位置,并且仍然实现高内存性能,就像嵌入查找中的情况一样。
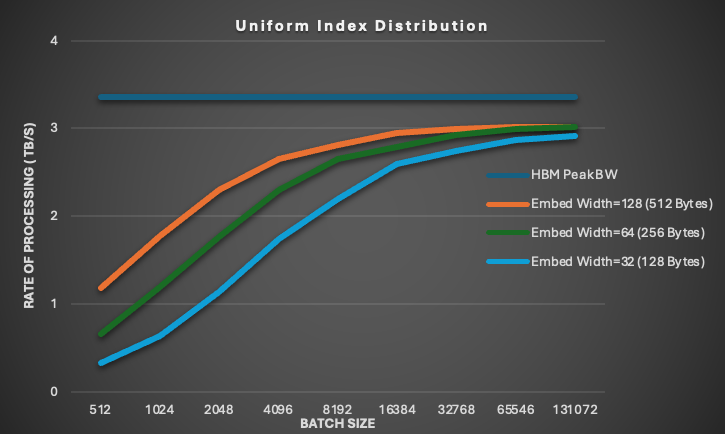
图 2 涵盖 10M 个类别;统一索引分布、fixed-hotness 格式,其中 hotness=64,float32 嵌入类型,sum 组合模式,和 1K 迭代。
由于缓存的带宽放大效应,GPU 在嵌入查找方面更加出色。为嵌入查找提供的索引往往遵循幂律分布,这意味着某些项目或行比其他项目或行更受欢迎。常用行保留在 GPU 上的 L1 和 L2 缓存中。这可以缓解内存系统的下游压力,并加快片上处理速度。
cuEmbed 用于提高嵌入查找性能的策略是最大限度地增加呈现给内存系统的 loads-in-flight 数量。这是由 Little’s law 推动的,该定律将并行处理的项目数量和访问的延迟与所达到的总带宽相关联。
我们提供更少的线程,每个线程都有更多寄存器,以增加专用于全局加载 (LDG) 指令的资源总量。我们还使用循环展开,通过从单个线程同时加载多个嵌入行来提高内存级并行性。我们使用向量类型 (例如 float4) 进行加载和存储,并将索引预加载到共享显存中,从而将加载粒度增加到每线程 128 位 (LDG.128) ,以降低索引访问的延迟。
图 3 显示了以 TB/s 为单位处理嵌入行的速率可能超过 8 TB/s,比 HBM 峰值带宽速率高 2 倍以上。

图 3 涵盖 1000 万个类别,Power-Law (PSX) 指数分布:α=1.05,fixed-hotness 格式,其中 hotness=64;float32 嵌入类型、sum 组合模式和 1K 迭代。
总之,在 H100 GPU 上运行的 cuEmbed 能够在各种配置和合理的批量大小下以 TB/s 的速率处理嵌入行。
如何使用 cuEmbed
cuEmbed 是一个 C++ header-only 库,您无需单独构建或安装。相反,请将 cuEmbed 作为子模块添加到您的项目中,并包含相关的 .cuh 文件以访问 API。
例如,要访问 embedding lookup 函数,请包含以下内容:
cuembed/include/embedding_lookup.cuh
向后传递需要对查找索引进行额外转换,例如 transposition:
cuembed/include/index_transformations.cuh
您还可以通过 CMake Package Manager (CPM) 将 cuEmbed 直接添加到您的项目中。将以下代码添加到您的 CMakeLists.txt 文件中,并将 my_library 替换为目标的名称:
CPMAddPackage(
NAME cuembed
GIT_REPOSITORY https://github.com/NVIDIA/cuembed.git
GIT_TAG main
OPTIONS
"BUILD_TESTS OFF"
"BUILD_BENCHMARKS OFF"
)
target_link_libraries(my_library cuembed::hdrs)
/examples/pytorch 目录包含将 cuEmbed 集成到 PyTorch 的示例。cuEmbed 前向、后向和各种辅助函数作为 C++ 扩展程序向 PyTorch 公开,这些扩展程序进一步封装在自定义 PyTorch 操作中。目前,cuEmbed 和本示例仅支持 torch.nn.EmbeddingBag 功能的子集。
有关更多信息 (包括详细文档和示例) ,请参阅 /NVIDIA/cuembed GitHub 资源库 。cuEmbed 完全开源。内核使用 C++ 模板设计,易于阅读,因此您可以根据需要扩展和增强这些内核,同时保留高性能所需的优化。
Pinterest 的成功案例:Faster recommender 训练
我们与 Pinterest 的工程师分享了 cuEmbed,以测试其在实际推荐系统工作负载上的性能。我们得到的反响鼓舞人心。
Pinterest ML Foundations 团队的 Chen Yang 表示:“稀疏或分类特征的嵌入查找通常是我们基于 GPU 的推荐系统模型中的瓶颈。在集成 cuEmbed 并将代码更改降至最低后,我们在关键产品排名和推荐 ML 工作负载中实现了 15-30% 的 GPU-roofline 训练吞吐量提升。”
总结
cuEmbed 为 NVIDIA GPU 上的嵌入查找提供高性能解决方案,通过优化的内存访问模式和有效的缓存利用率,实现超过原始 HBM 带宽的吞吐率。通过开源此库,我们的目标是使社区能够针对不同的嵌入用例定制和扩展这些优化。
无论您是构建推荐系统、图形神经网络,还是使用语言模型,cuEmbed 都能以最少的代码更改显著加速嵌入操作。
后续步骤
cuEmbed 为 NVIDIA GPU 上的嵌入查找提供高性能解决方案,通过优化的内存访问模式和有效的缓存利用率,实现超过原始 HBM 带宽的吞吐率。通过开源此库,NVIDIA 旨在使社区能够针对不同的嵌入用例定制和扩展这些优化。
无论您是构建推荐系统、图形神经网络,还是使用语言模型,cuEmbed 都能以最少的代码更改显著加速嵌入操作。
- 从 /NVIDIA/cuembed GitHub 资源库下载 cuEmbed。有关 Python 集成模式,请探索
/examples目录。有关高级使用场景,请参阅 cuEmbed 文档 。






